
I have been testing various AI models locally via Text Gen WebUI and in this post I will tell you my favorite AI models that you can run on a modest PC hardware. The models have been tested and confirmed working on Ryzen 3600 + RTX 3060ti with 8GB VRAM and 16GB System RAM.
My Top Four Picks for GPUs like 3060ti, 4060ti with 8GB VRAM
- Meta-llama_Meta-Llama-3.1-8B-Instruct
- Deepseek-ai_deepseek-coder-6.7b-instruct
- Teknium_OpenHermes-2.5-Mistral-7B
- NousResearch_Hermes-2-Pro-Llama-3-8B
How to download use the AI models locally via Text Gen Web UI
These models produce good results as per their specifications of 7B,8B parameters, these can be used on your local PC without paying to the cloud providers, to install them simply go to Model tab -> Download and input the model name.
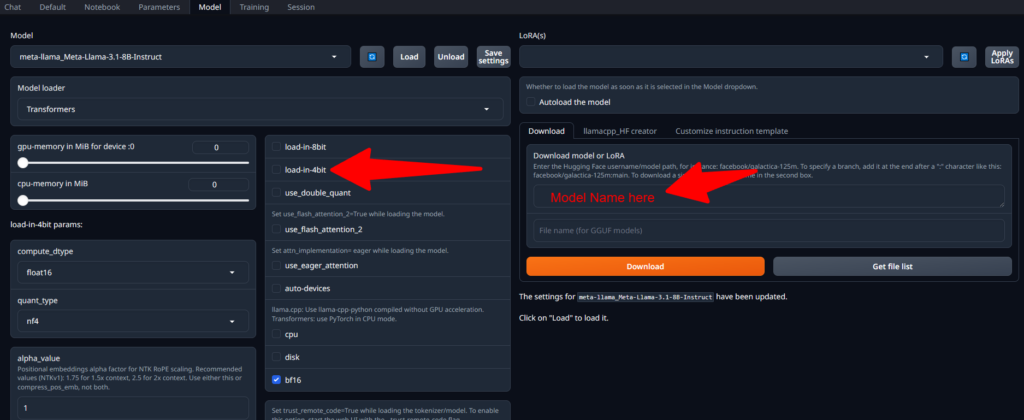
Only step that you will need to make sure is the setting box that read “load-in-4bit”, otherwise many models will fail to load or work properly. These models give around 10-15 tokens/second for text generation, which is pretty good for a locally installed AI model.
About that google_gemma-2-9b Model.
I had high hopes with this model but it fails to work even in 4 bit mode via Text Gen Web UI. It loads successfully but do not work. Everything was updated.
Which is your favorite ~8B AI model?, let me know in comments.
Update: March 8, 2025
To get the best LLM model for your card, find the 4bit gguf of your LLM from https://huggingface.co/bartowski
During my testing, I do not like ~8b models at all, most are a waste of time. I now only test and run ~ quantized 14b i.e ~10gb models on my another PC with 3080ti with 12GB VRAM.
Will be making post about it soon with best models.
TLDR: Minimum 12GB VRAM graphics card, Recommended: 16+ VRAM graphics card.